Why you need a robust alerting system - how we caused 9 days of silent downtime
We are working on a service called Notify Me - it’s a simple update tracker whose core function is to send you a notification whenever a page you are tracking changes it’s content.
We have around 3200 users, mostly on freemium plans, and from 13th of September until 24th of September we haven’t sent a single site update to 99% of them, and we discovered that our service wasn’t working properly by chance. In this post, I’ll try to explain how this happened.
Our stack
Our current stack is a weird mix of Google Cloud and bare metal machines since we are in the middle of migrating everything to self-hosted k8s cluster on Hetzner.
This decision always rises quite a few eyebrows, so long story short: Between the three of us, we have extensive DevOps experience, we love setting up our own stuff and we want to spend as little money as possible on hosting. Since we got that out of the way, we can continue with this post mortem.
Scheduling logic
We have a bunch of microservices that we use to run everything. Particular service that caused this failure is called page-scheduler. It’s purpose is to continuously check pages and send them to processing if needed. If scheduling stops, no one gets their updates.
Page checking is accomplished by having the next_scrape field in our database so we know when was the last time the page was scraped. This field is automatically updated by another service which processes the pages sent from scheduler so we know when we should recheck the page (schedule is determined by the plan user has - better plan means more frequent checks).
We do all of our alerting using standard grafana + prometheus stack and we had specific delay metrics which we monitored from time to time, but we didn’t set up alerting.
The Problem
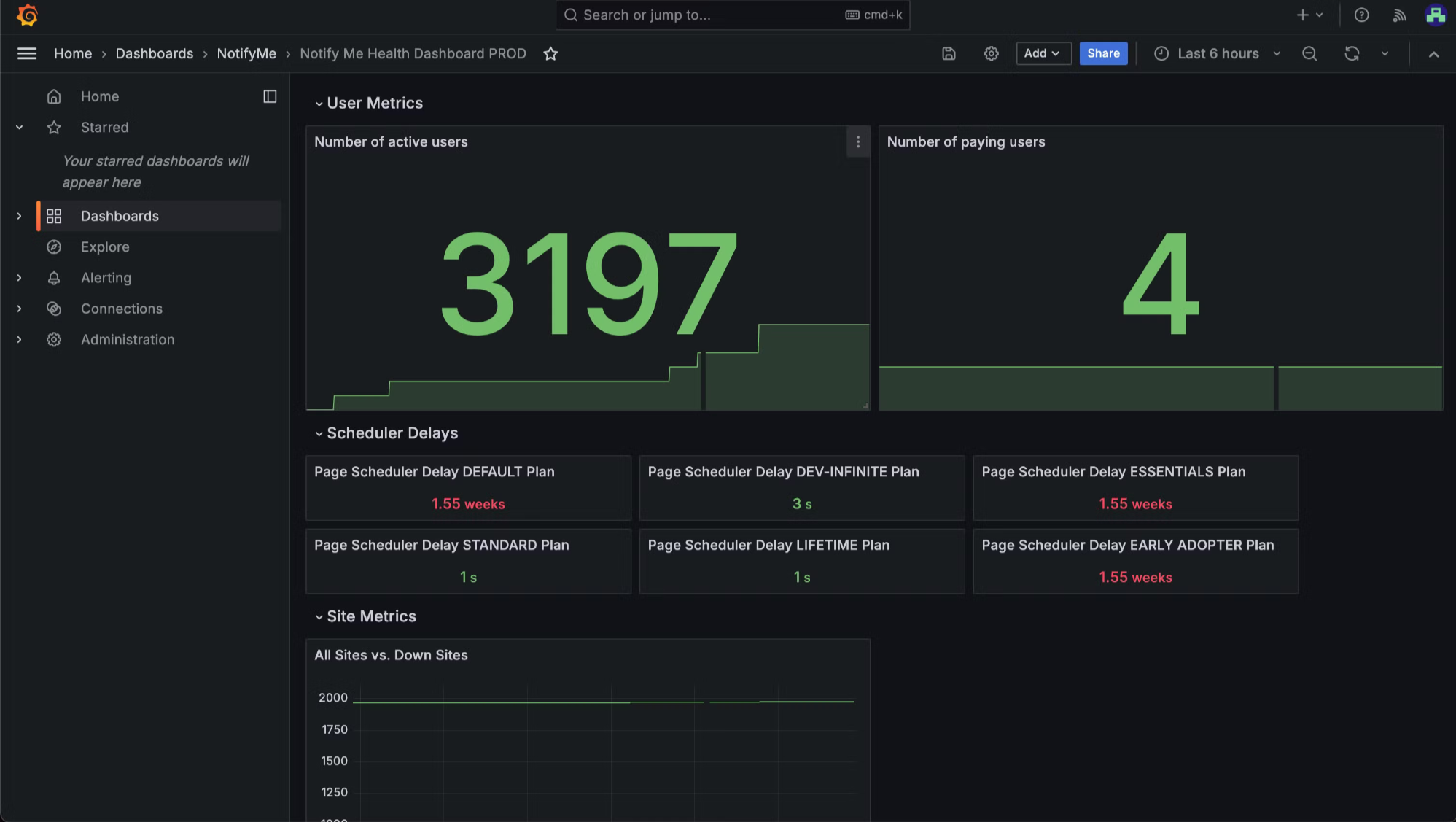
We realized that something is wrong when we accidentally took a look at the metrics while solving completely unrelated problem and saw the following on the dashboards:
For reference, this is how the dashboard looks when everything is okay:
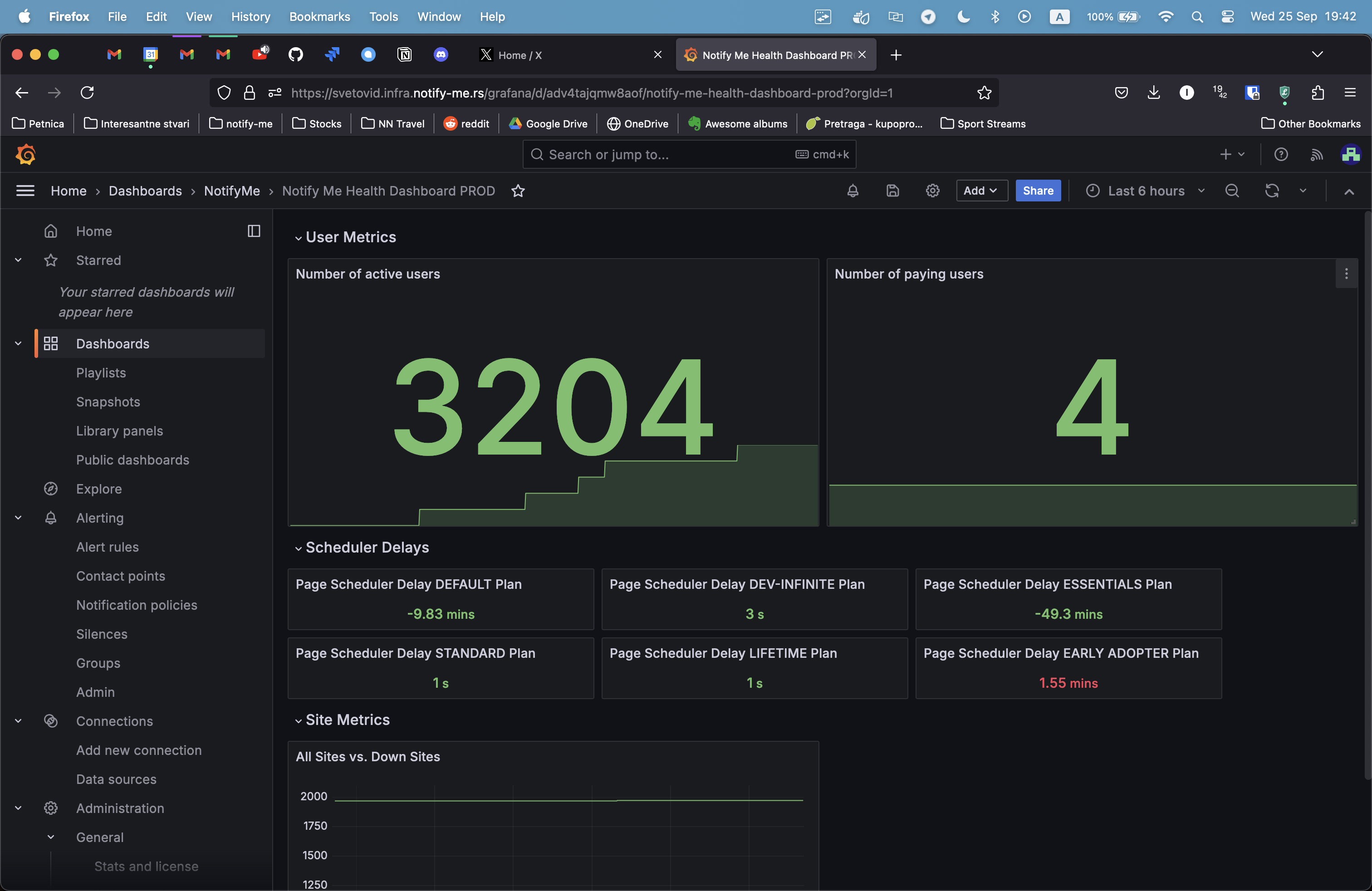
There is still some delay present, but it’s in minutes, not weeks! And most of the times, delay should be in the green anyways. This meant that majority of our users haven’t got a site update in more than 9 days on average.
The Solution
After the usual couple of minutes of panic and questioning of life choices that have led us to this situation, we started looking at what could be causing the problem.
We quickly realized the problem was related to introduction of soft delete functionality which we recently implemented so we could see which sites people who deleted their account have tracked. Soft delete meant that old sites weren’t permanently deleted from the database, instead they would just get flagged as deleted. This proved to be the source of the problem, but the tricky part is that it wasn’t obvious.
Our scheduler is getting batches of sites from the database, ordered by the next_scrape field. What started to happen is that we pulled deleted sites from the database, which would then automatically be ignored by our scraping pipeline since they were technically deleted. As the number of deleted sites grew, at one point, all the sites which were pulled in a single batch were deleted which meant that we continuously pulled the same sites which were never getting updated. Our batch size is 50 sites at once, which is a completely arbitrary value we choose, if we had taken a bigger batch size, this problem would be undetected for months.
The Fix
After we realized what was the problem, we did the following two things:
- When the site gets deleted, we need to update the
next_scrapevalue to a huge number so we don’t fetch those sites - We need to run the one-off script which will updated already existing db entries with a huge number
Whole incident from detecting the problem to resolution didn’t took more than 1 hour, which was great.
The Takeaway
All of this could be avoided and / or caught very early if we had proper alerting systems in place. We use Discord for our alerts and we already have some alerts set up that are being send to a dedicated discord channel. We’ve fixed this now, but there is no excuse for not having these set up in the first place.
We already added the missing alerts and we’ll hopefully catch these kinds of problem much earlier next time.