What Happens When Your Cloud Provider Has Downtime?
Introduction
When building software, having available VMs and instances in general is a given, and when that stops being true, as it did with our infra on Hetzner really weird stuff tends to happen.
When I started writing this blog post, we were slowly digging ourselves from biggest outage we had. Which was, ironically enough, caused completely by our cloud providers fault. So I decided to write about it while the memory is still fresh and while were are still actively looking at our metrics.
Our setup
Notify Me is completely bootstrapped so we are trying to save as much money as possible. We are running our whole infra on Hetzner services and we are using kops to manage our k8s cluster.
We literally had 0 incidents for the last 2 years and then everything exploded on the 1st of June.
Timeline of our downtime from June 1st to June 3rd
June 1st, 9:21 Hetzner sends reminder notification about outdated controller
We are running all our services with kops, which is a tool for provisioning kubernetes clusters. Instead of doing everything manually, kops automates 95% of the setup required.
Since kops uses hetzner APIs internal, this notification meant that it’s probably time to update our clusters - something that we’ve done multiple times before, with no issues.
Screenshot of an email we got:
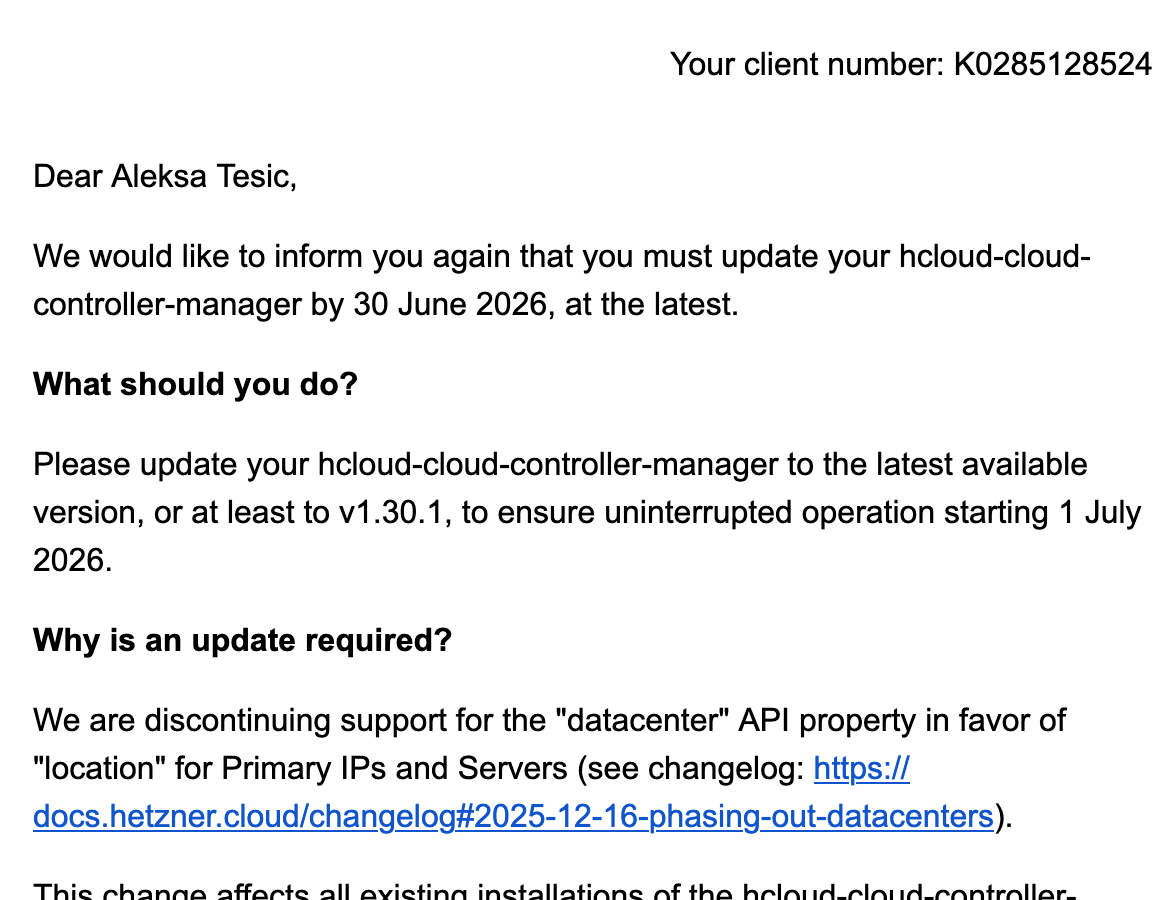
Since this was the 2nd reminder we got, and we had some free time, we decided to just get over with this and update our cluster.
June 1st, 11:19 Our ARM based machines are no longer available
We’ve used the CAX instances on Hetzner which were ARM based, mostly because they were cheaper and because all of our development already happens on ARM based MacBook chips, so everything worked pretty much out of the box.
When kops starts the cluster update, it simply requests a new machine of the same type (CAX31 in our case) and adds the new update node to the cluster. This is done via some Hetzner API so we don’t have control over it. Problem was that when we tried the update, no ARM based machines were available due to everyone suddenly wanting to run their own AI infra on hetnzer so our update was just stuck in a weird state.
You can see all ARM machines being unavailable:
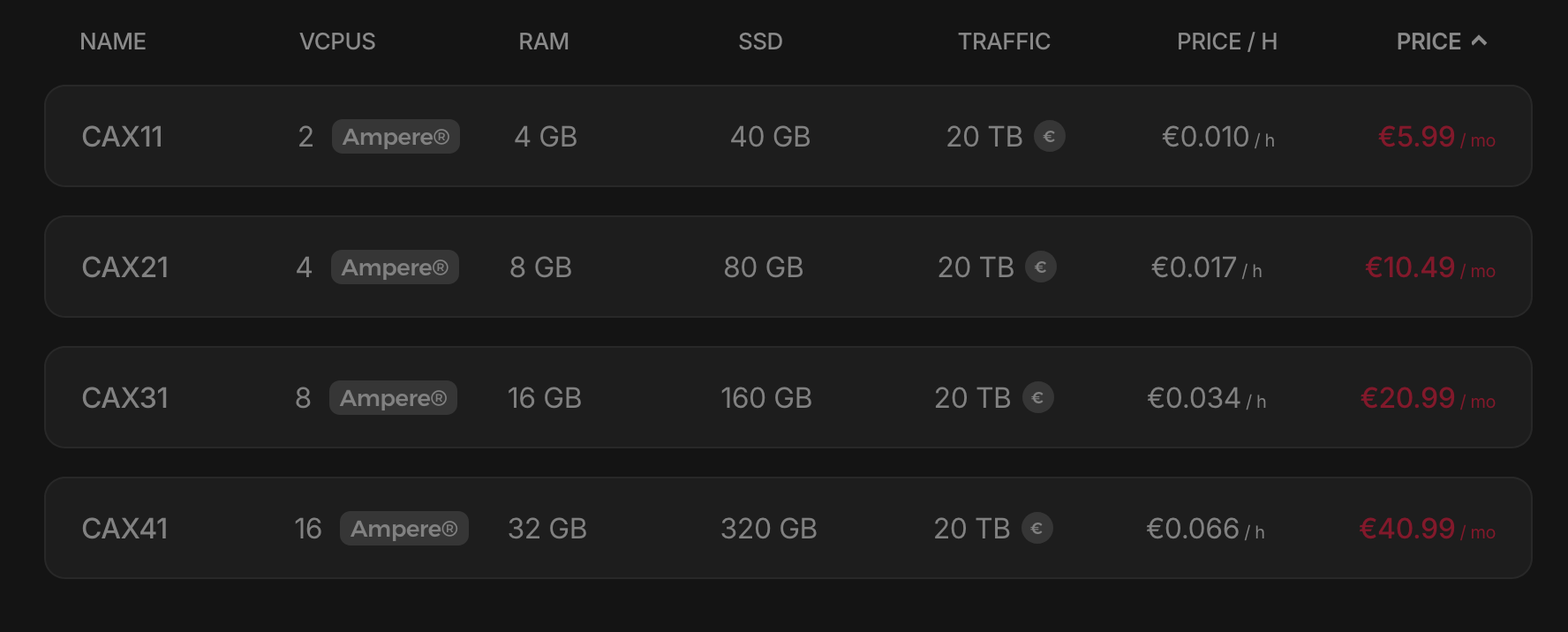
Was this a blunder from our side, because we could’ve checked this? - I guess so, but on the other hand, we’ve done the exact same procedure multiple times, and we’ve never encountered a similar problem.
June 1st, 11:39 We are switching to more expensive x64 machines
At one point we just decided to cut our loses and simply switch to more expensive x64 machines, only to find out that optimized performance machines are completely unavailable regardless of architecture. We decided to bite the bullet and switch to dedicated performance VMs - it literally didn’t make any difference for us but it was twice as expensive. At this point we were already down for a couple of hours.
June 1st, 12:11 Physical server outages
As soon as we switched to more expensive machines everything seemed to be finally resolving. Little did we know that the physical server rack where some of our VMs were was unavailable. This only worsened our already fragile cluster state. By pure luck our control node landed on a machine which wasn’t in an incident. At this point there was literally nothing we could do apart from waiting for our 2 worker nodes to start responding again.
We were in a weird state where kops tried to spin up a node which became unavailable due the physical server being in an incident so we had a machine that was just kinda dangling not attached to our cluster - We cleaned this up at some point later in the day.
June 1st, 14:02 Setting up banner on our website that we are completely down
At this point we just accepted that we were going to be down for quite a while, and since our website was hosted on Cloudflare, we were technically still online, but no one could do anything that required backend interaction. In short, they could only navigate through public pages.
June 1st, 14:50 Cluster recovery
We received a notification that nodes were out of the incident and we had succesfully set our cluster back up. Last thing that was left to do was to rebuild / change every image we had to a x64 based version.
This took a while because, of course, some repositories we used were no longer available (thanks bitnami) and some of them were custom build arm versions so replacement wasn’t straightforward.
June 1st, 22:34 All services operational and 11.2h message lag
We finally got all services up and running and we needed to tackle another problem - huge lag we had.
Notify Me works with a queue based system where we have a scheduler service which constantly checks all sites and if they need rechecking (based on the interval user set) it triggers a new check. We have a lag metric which shows the oldest check time we have in our database. When everything is working correctly this lag is positive, due to all new checks being in the future.
But, since we were out for half a day, our lag for all 12000 sites were more than 11 hours.
Number of replicas we had is set up assuming that we won’t have to process 12000 sites at once, so this was were round 2 of incidents began.
In non-technical terms, imagine that you have a post office with 5 postmen. They’ve been there for years and they know the average number of parcels / letters they receive each day. Number can vary slightly of course, but nontheless, they are somewhat prepared.
Now, imagine that one day, they simply get 10 times the number of letters they usually receive, and they need to deliver them all ASAP - That’s what happened to our services once we got up and running.
Luckily, since we were running on k8s, we manually increased number of replicas for the affected services and lag slowly started coming down.
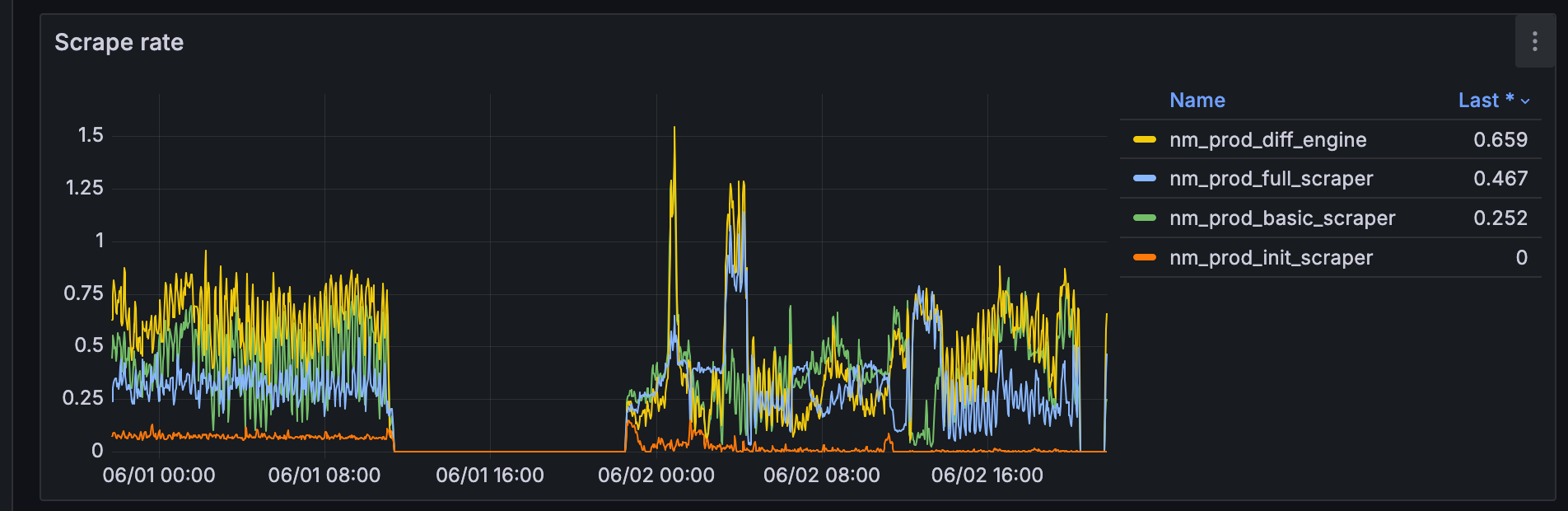
In the image below you can clearly see the huge message lag, as well as, at that point, still completely dead services.
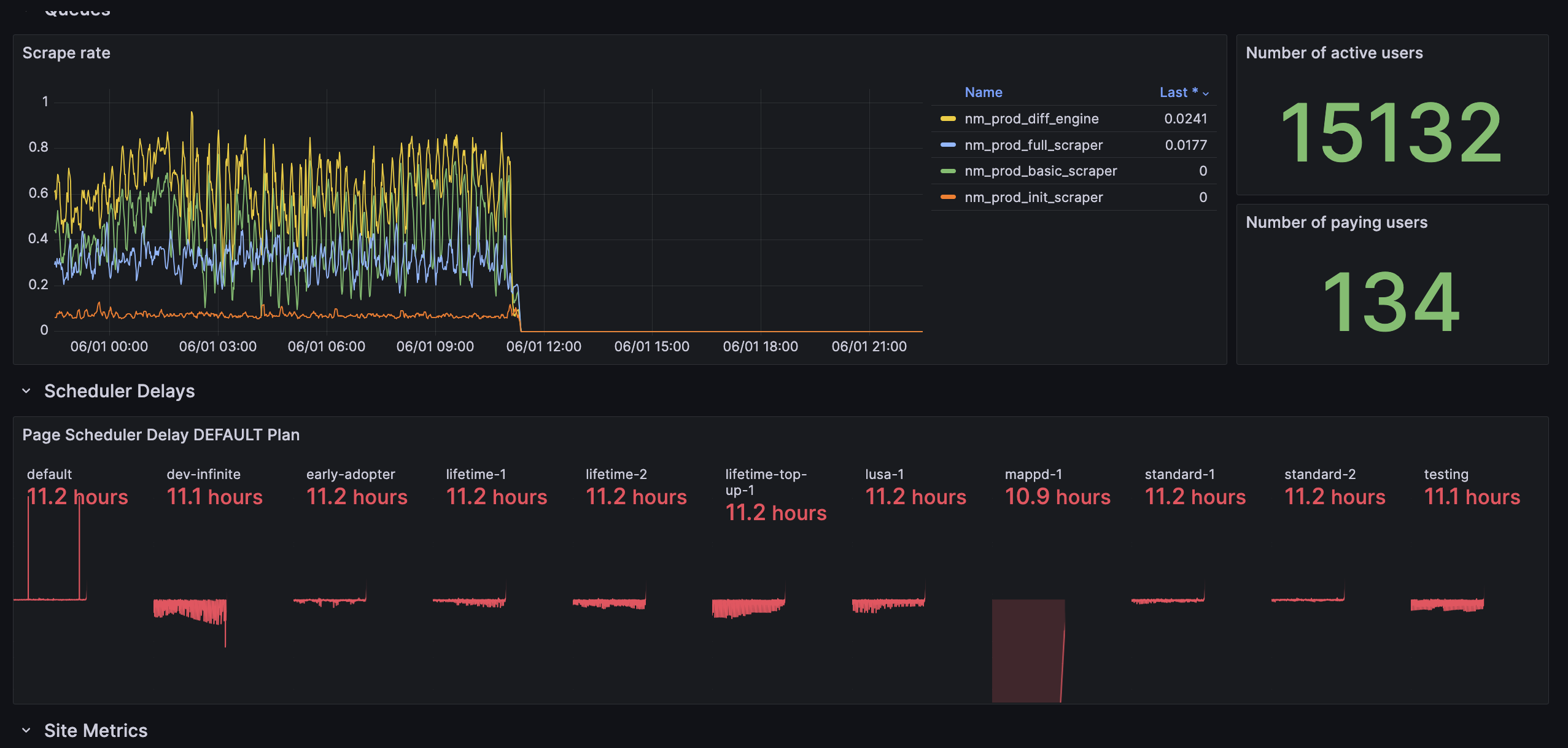
If you were wondering how metrics look like when queues start getting bombed by messages:
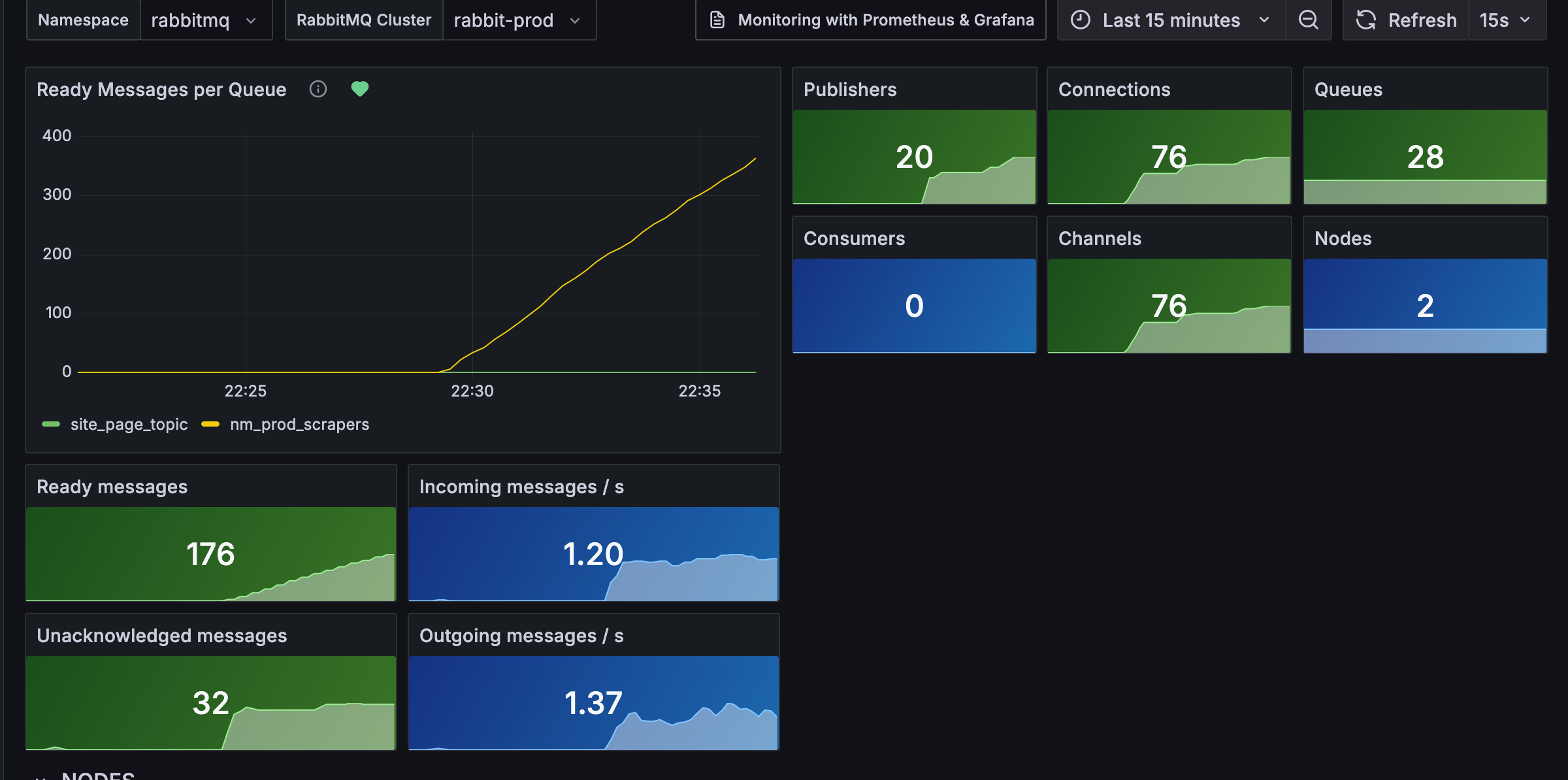
June 2nd, 12:24 Proxy goes down
At one point, we realized that message processing was getting painfully slow, even though we had scaled to more worker nodes. We saw that all of our requests were timing out.
Site timeout is, of course, expected, but it shouldn’t happen for literally every site we had in our database. Mind you, this was propagating directly to our users through site status on frontend.
After a short investigation we realized that our proxy service, which is set up on a completely different machine since we needed it to be in the US so we could have a US IP, simply stopped working.
Long story short: complete VM restart solved the proxy issue, and while we were solving that, we simply turned of proxy for all sites.
June 3rd, 10:11 All systems back to normal again
After that last proxy related incident, we spend the whole day monitoring the logs and message queues so we were sure everything was slowly going back to normal.
Here is a screenshot of our metrics where you can see the outage and then subsequent spikes and then finally slow normalization of the load:
Takeaways
- Be patient. When stuff like this happens, sometimes the only thing you can do is wait. Remind yourself that this is not the first (nor the last) time where shit hits the fan and also remind yourself that it, in the end, it usually gets sorted out.
- Know limitations of your system. We already knew what was going to happen when we start processing sites again, and we were prepared for it. Same goes for anything similar that you have on your systems
- Be transparent. Let your users know that something is wrong and that they will have a service disruption. If you are a small company, trust is very hard to build, but it’s easily lost.
All in all, we’ve survived the biggest outage we had and our trust in Hetzner is pretty much gone. As a cherry on top, they’ve recently raised their prices by 300% which is insane.
We are most likely going to move through AWS if we manage to get some startup credits.
Hope this helps!
Until next time o7