How We Burned Through Our Quarterly Hosting Budget In 3 Days
Introduction
Our main way of cross service comunication at Notify Me is via queues. In our case, that’s a single rabbitMQ instance which handles all of our queues.
All of our queues have a pretty simple retry logic - If something fails, throw exception, and requeue the message.
Important thing to have in mind that our core business logic is heavily relying on reading from S3 buckets (that were at the time of this incident hosted on AWS, which will be important later).
We have a service called diff_engine which continuously checks and compares the latest version of the site and the one we have from before, so we can send site updates properly. This service produces very large number of GET requests to our buckets (essentially just reads a lot of data).
The Problem
We firstly noticed that something weird was happening pretty much by accident. We have Grafana monitoring in place and we have one main dashboard with the most important metrics which I’m often checking to see our user count. During one of those checks I noticed a weird pattern in the scrape rate metric for one of our services. Queue that’s important to us is called nm_prod_diff_engine
How the graph looked:
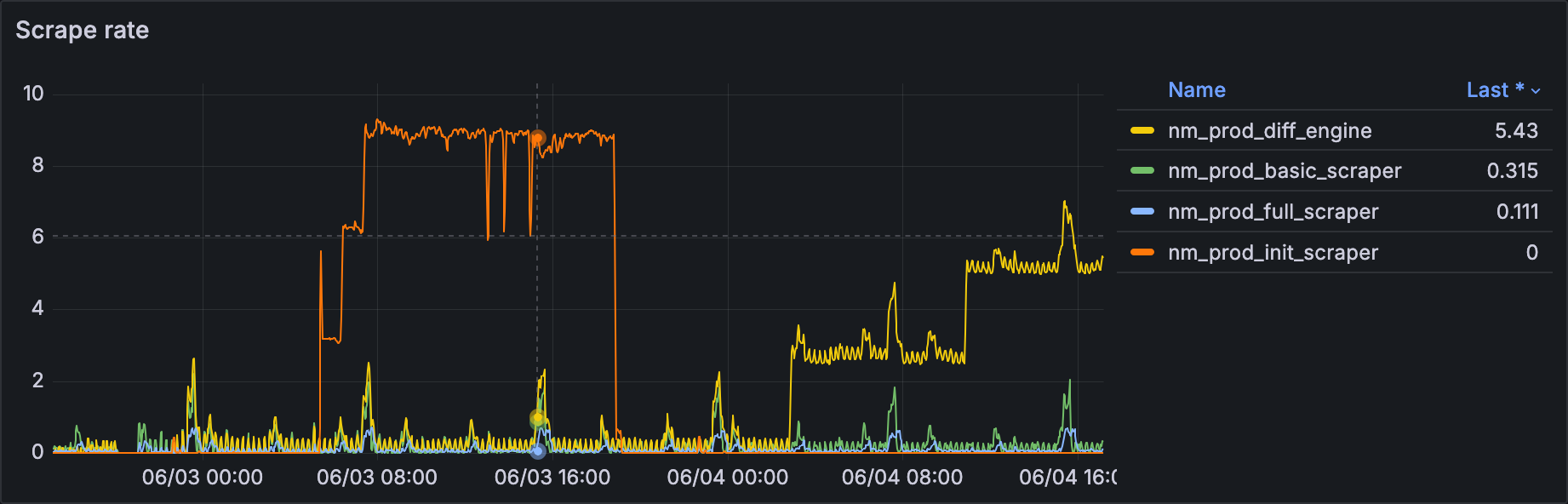
What was expected:
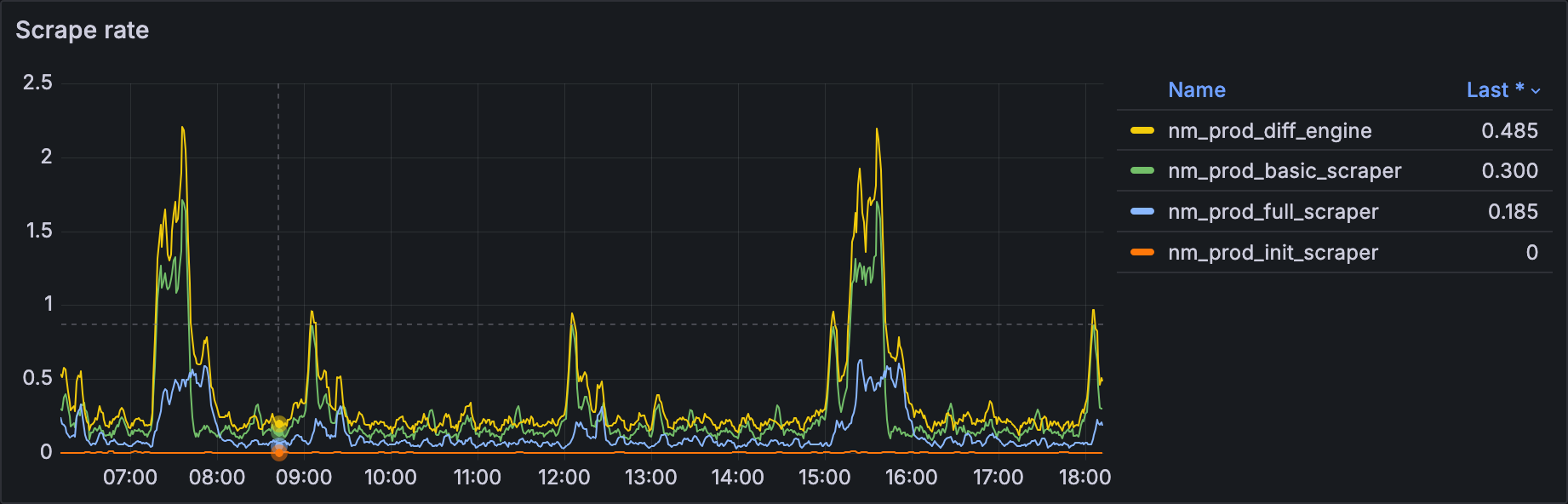
Scrape rate metric is basically how many messages is one of our services processing at any given moment, and the expected look of that graph is that it has spikes.
One thing that you’ll notice in normal scenario is that, after the initial spike, service had almost no load. This is due to the way we are processing our sites. Majority of our users are checking their sites every 8hrs, which is reflected on our workloads.
We acknowledged the weird pattern that was happening, but we didn’t do anything else about it. All other metrics were normal, everything was functioning and we had no reason to think that something was out of place. So we dismissed the problem as intermittent and kinda forgot about it.
The Aftermath
Fast forward 3 days later, we are all gathered in person for a mini hackathon session. Among other things we did, we wanted to see how much will our new AWS bucket set up cost us. We moved from Hetzner to AWS due to Hetzner being very unstable and causing 3 serious outages.
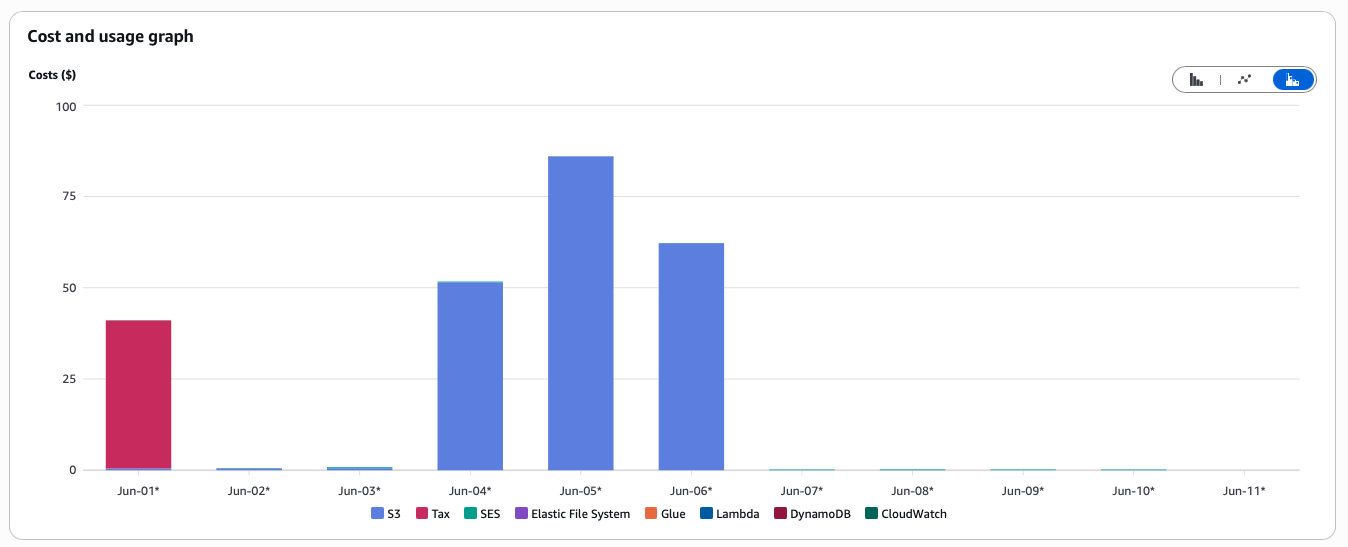
To our shock, we saw that estimated bucket usage for 3 days was $250.
For reference, our entire infra bill for the whole month was around $65 at that point.
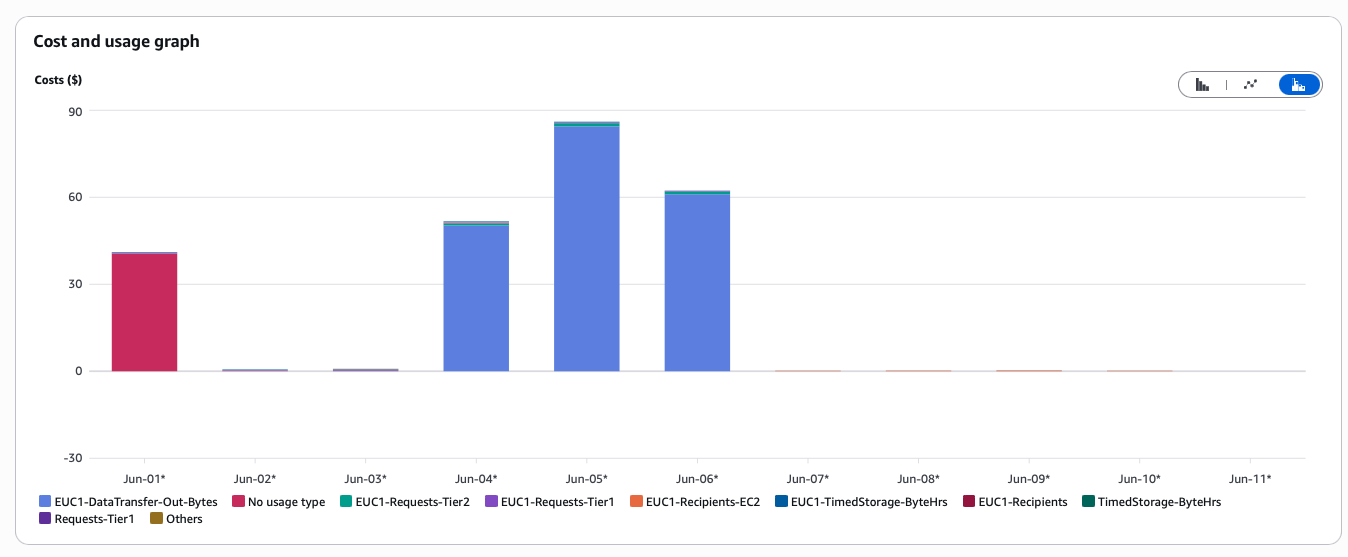
We immediately scrambled to see wtf was going on, and we soon realized that our egress cost was going through the roof. While we expected to have some egress cost, due to our cluster not being hosted on AWS, hence having egress fees each time we read from the bucket, it didn’t make any sense to us why the cost was that big.
AWS price breakdown:
Bucket price breakdown (clearly showing that the egress was the one causing the bill to explode):
The Fix
This was the point where we remembered the weird graphs from before, and as it usually happens, we immediately realized the root cause of the problem. That issue we thought was intermittent was actually still going on, and its duration perfectly aligned with the increased AWS bill.
Looking at the service logs, we quickly realized what was the issue. Service in question used buckets to pull the old and new versions of the site that needs to be checked for the changes, and, based on those files, it determined whether any changes have been happening.
Logic went like this:
- Service receives a message from the queue.
- It tries to fetch the old version of the site from the S3 bucket.
- It tries to fetch the new version of the site from the S3 bucket.
- If any error occurs (e.g., network issue, file missing), an exception is thrown.
- The message is requeued for retry.
This cycle repeats indefinitely for problematic messages, causing repeated S3 reads and escalating egress costs. This also explained the weird spikes we saw in our graphs.
Fix was simply improving the error handling logic and not sending the message for retry in some specific cases.
Conclusion
Even though we had solid alerting in place, as well as budget alerts set up on AWS, we still got burned with a huge AWS bill, and by sheer luck, we found out about the issue before the cost was even bigger.
There were multiple reasons for this failure:
- We saw the weird pattern but we decided to ignore it since everything worked fine
- Although we had budget alert set up on amazon, we silenced it, since it was set to a very small amount that wouldn’t be enough for buckets.
- We never raised the amount and unsilenced the alert
- We had bad retry mechanism in our service, causing unnecessary reads to buckets
Price for this mistake is in this case pretty measurable - $250, which is what we usually spend in 4 months
I hope this was helpful!
Until next time o7